al
al | Celera cracks genetic code: Biotechnology company Celera Genomics Group announced Thursday 4/06/2000, that it completed the first step in unlocking the human genetic code (sequencing of the DNA ), and that its researchers have identified all the chemical letters that make up the genes of a human. The discovery announced by the company, PE Celera Corp. of Rockville, Maryland, focused on the first of the six different living people its researchers are studying to map the human genome.This is the first time any group of researchers has claimed to make such a discovery. Celera began sequencing the human genome last September, promising to finish the mapping project well before similar efforts by the Human Genome Project, an international consortium. |
al |
The project to map the human genome was launched by the U.S. government in 1990.The mapping of the human genome is considered a major scientific advance that will provide researchers with new insights into what role genes play in causing disease.
Chromosome & DNA Structure
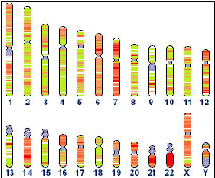
The nucleus of each human cell contains more than four metres of DNA packaged into 46 chromosomes.

|
|
 
|
|
This genetic code consists of a sequence of bases which is unique to the organism. Human DNA has more than three billion of these bases. The International Human Genome Project aims to determine the sequence of all the DNA in humans :
A ) Chromosome |
 B) B) |
c) |
D |
 E
) E
) |
 |
 G) G) |
|
 ) Double- standed DNA
) Double- standed DNA |
L) Sequence of Chemical components
called Bases  |
The human genetic pattern, or genome, is a biological map laying out the sequence of 3 billion pairs of chemicals that make up the DNA in each cell. All human DNA is contained within 23 pairs of chromosomes.
|
Compenents Bases Each chemical is assigned one of four letters A,C,T, or G -- representing the chemicals adenosine, cytosine, thymine and guanine. Once those chemical letters are sequenced, scientists can compare the patterns in different people to determine where there are genetic variations that could be the cause of countless diseases . Double-stranded DNA  |

|

 |
The Human Genome Project (HGP) is an international research program designed to construct detailed genetic and physical maps of the human genome, to determine the complete nucleotide sequence of human DNA, to localize the estimated 50,000-100,000 genes within the human genome, and to perform similar analyses on the genomes of several other organisms used extensively in research laboratories as model systems. The scientific products of the HGP will comprise a resource of detailed information about the structure, organization and function of human DNA, information that constitutes the basic set of inherited "instructions" for the development and functioning of a human being. Successfully accomplishing these ambitious goals will demand the development of a variety of new technologies
Code Matrix Location: Exodus 5:4 to 13:20
The Central Term is " human genome ", and it appeared only once in all of the TORAH, with a skip sequence ELS of (-1727).

|
 |
|
In Cluster 2, we searched for the term "DNA Sequencing", and in the proximity of this term we found the following related and encoded words: 
|
 |
|
|
Webmaster analysis: What is the statistical relevance of the Cluster 1 matrix? If we add up the positive matrix R-values from the Cluster 1 Matrix Report, we get a cumulative matrix R-value of 6.133 (using the text R-value for the main term). Then taking the antilog of the total matrix R-value, we get 1,358,313.4. That means that cluster 1 is very relevant when viewed statistically from a frequency point of view. There is 1 chance in 1,358,313 of the matrix occurring with all of the terms in such a small matrix. Or as stated in expected occurrence for the matrix, we'd expect 0.0000007 occurrences. Let's restate it in another way much more conservatively. We would normally divide the probability by the expected number of occurrences of the main term in the text for the ELS search range of -1727 to 1727 in the Torah, but that is less than 1, so it doesn't change the results. We can also divide it by the row split to account for looking at 1-7. 1,358,313 divided by 7 equals 194,045. Therefore, conservatively stated, the probability of cluster 1 above is 1 chance in 194,045. This is a very significant matrix.